知识库
按创建、导入、处理、检索验证的顺序搭建一个真正可用于 RAG 的知识库。
功能概述
知识库用于把 PDF、Markdown、网页或其他文档资料转换成可检索的知识内容。
只有文档被正确导入、处理并命中,Agent 和工作流才能真正基于资料回答问题。
适用场景
知识库适合承载:
- 产品文档
- 帮助中心
- 培训资料
- 公司制度
- 项目交付资料
- FAQ 和网站页面
前置条件
开始前建议准备:
- 2 到 10 份结构清晰、版本较新的资料
- 一个可用的 Embedding 模型
- 3 到 5 个可用于检索测试的真实问题
操作步骤
第 1 步:进入知识库列表,先看现有知识结构
进入工作台的 知识库 页面,先确认当前已经有哪些知识库。
这一步重点看:
- 命名是否清晰
- 每个知识库大概有多少文档和分块
- 是否已有可直接复用的知识库
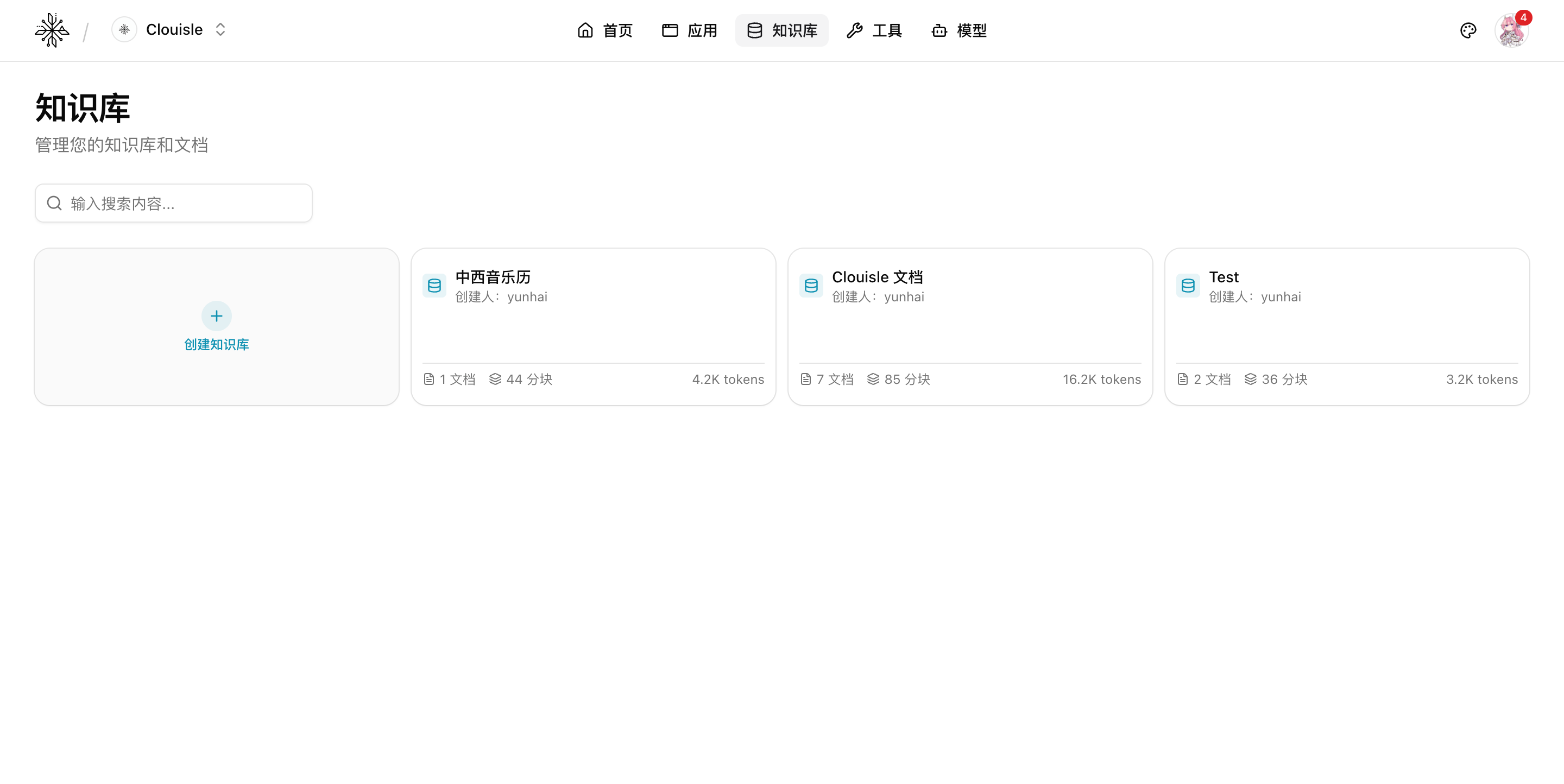
完成这一步后,你应该能决定是新建知识库,还是沿用已有知识库继续扩充资料。
第 2 步:创建知识库并填写基础信息
创建知识库时,建议先明确:
- 名称
- 描述
- 所属团队
名称最好直接体现资料主题,例如“产品帮助中心”“企业制度库”,不要只写“测试知识库”。
第 3 步:选择 Embedding 模型并设置分块参数
知识库创建时,至少要确认两类基础参数:
- Embedding 模型
- 分块参数,例如
chunk_size、chunk_overlap
第一次建议先使用保守配置,不要一开始就频繁调参数。
目标是先得到一版可测试的结果,再基于命中情况优化。
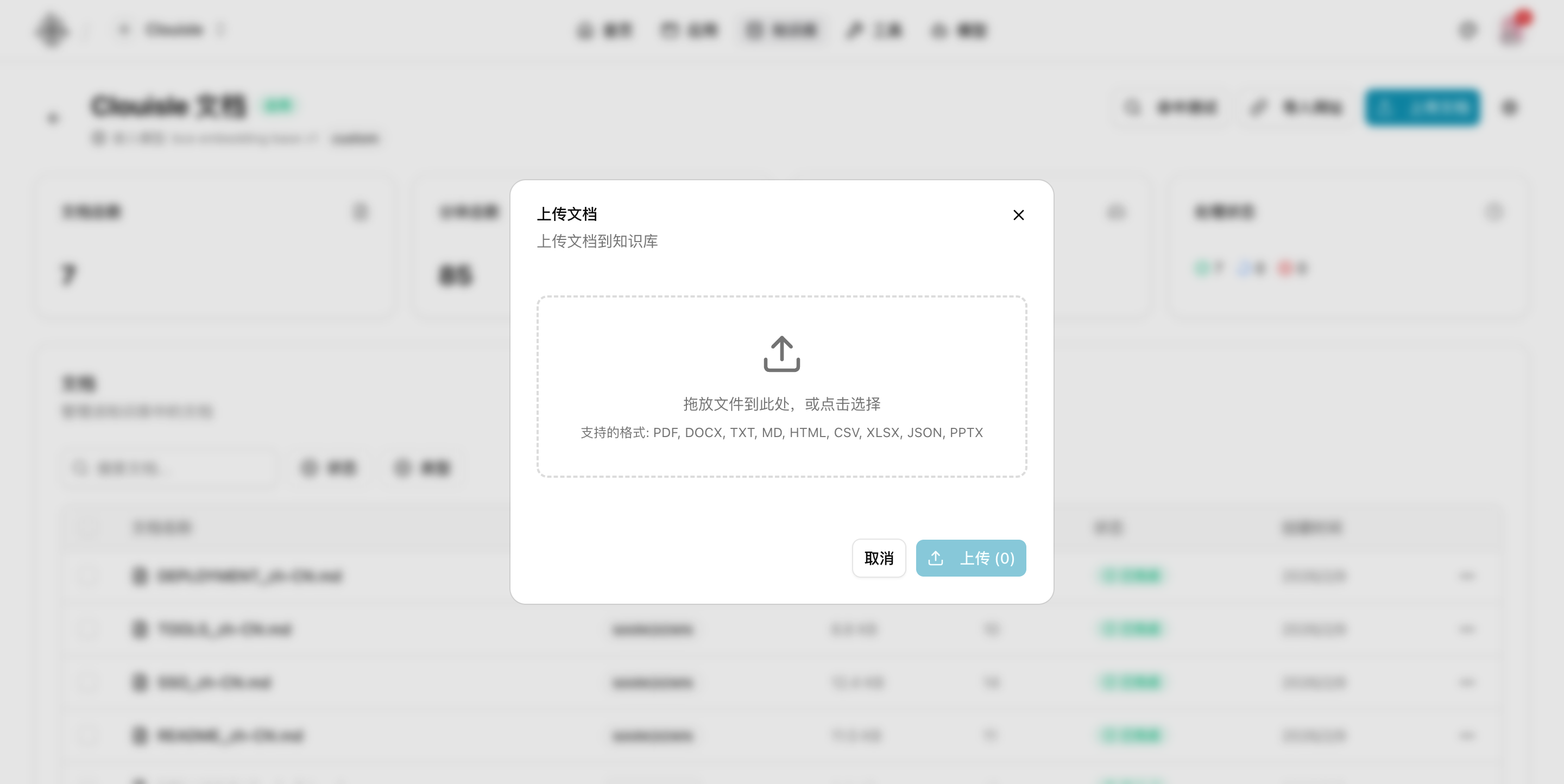
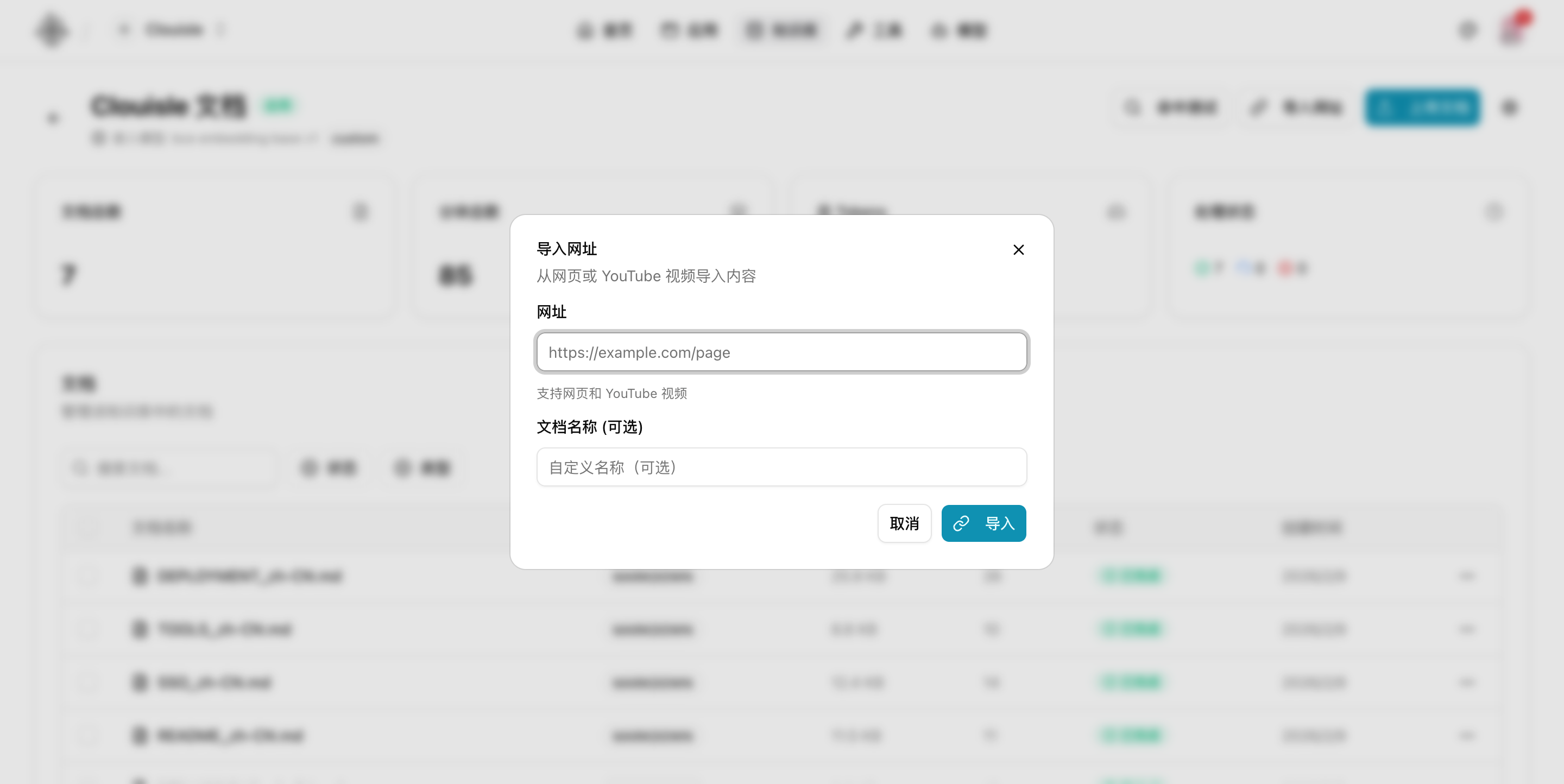
第 4 步:导入第一批核心资料
第一次导入时,建议只放少量高质量文档,而不是一次把所有资料全量导入。
优先选择:
- 结构清晰
- 内容稳定
- 主题集中
- 可直接用于回答用户问题
的资料。
第 5 步:进入知识库详情页,查看文档处理状态
导入完成后,进入知识库详情页,重点确认:
- 文档数量是否符合预期
- 处理状态是否成功
- 分块数量是否明显异常
- Token 估算是否大致合理
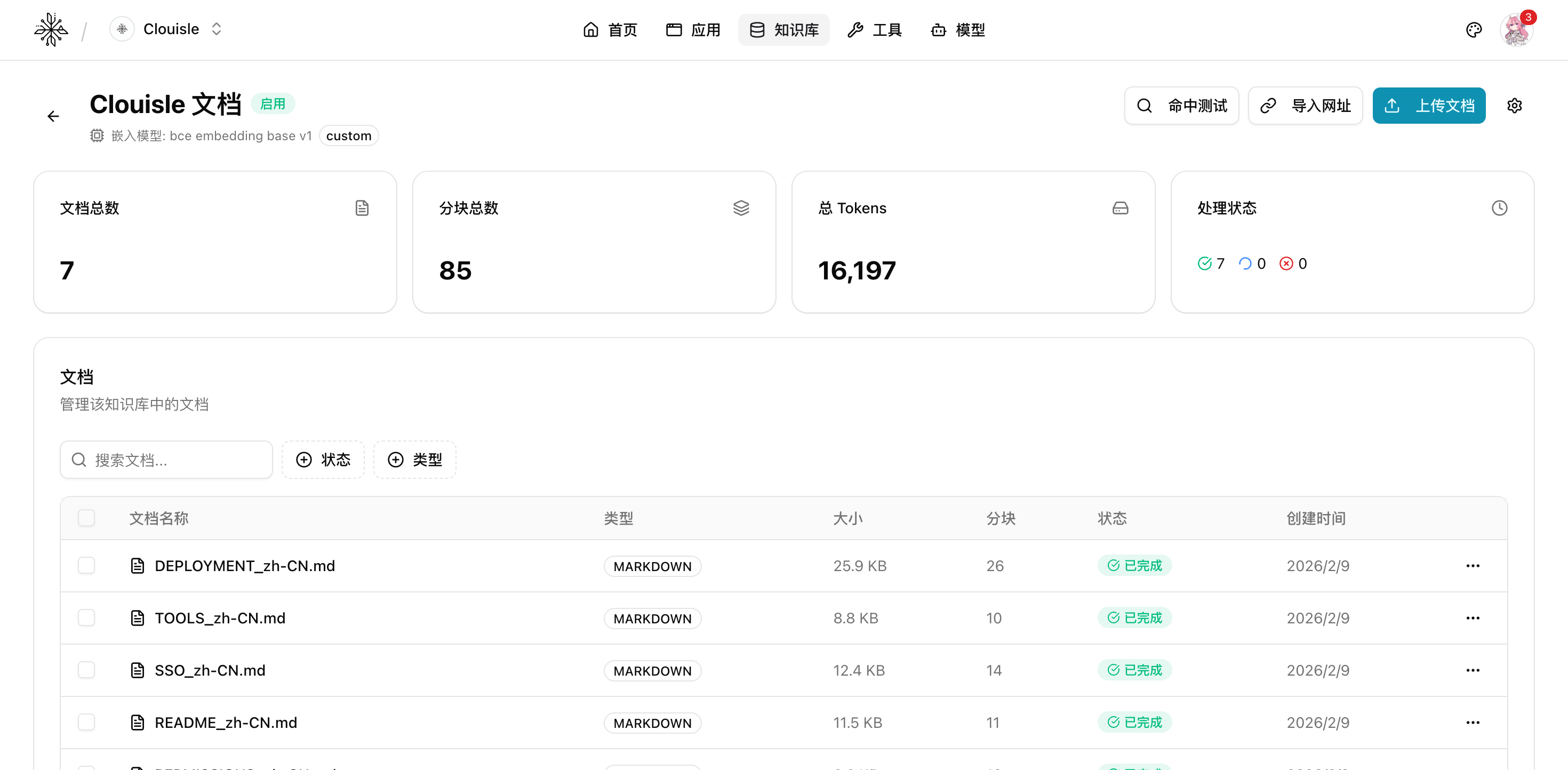
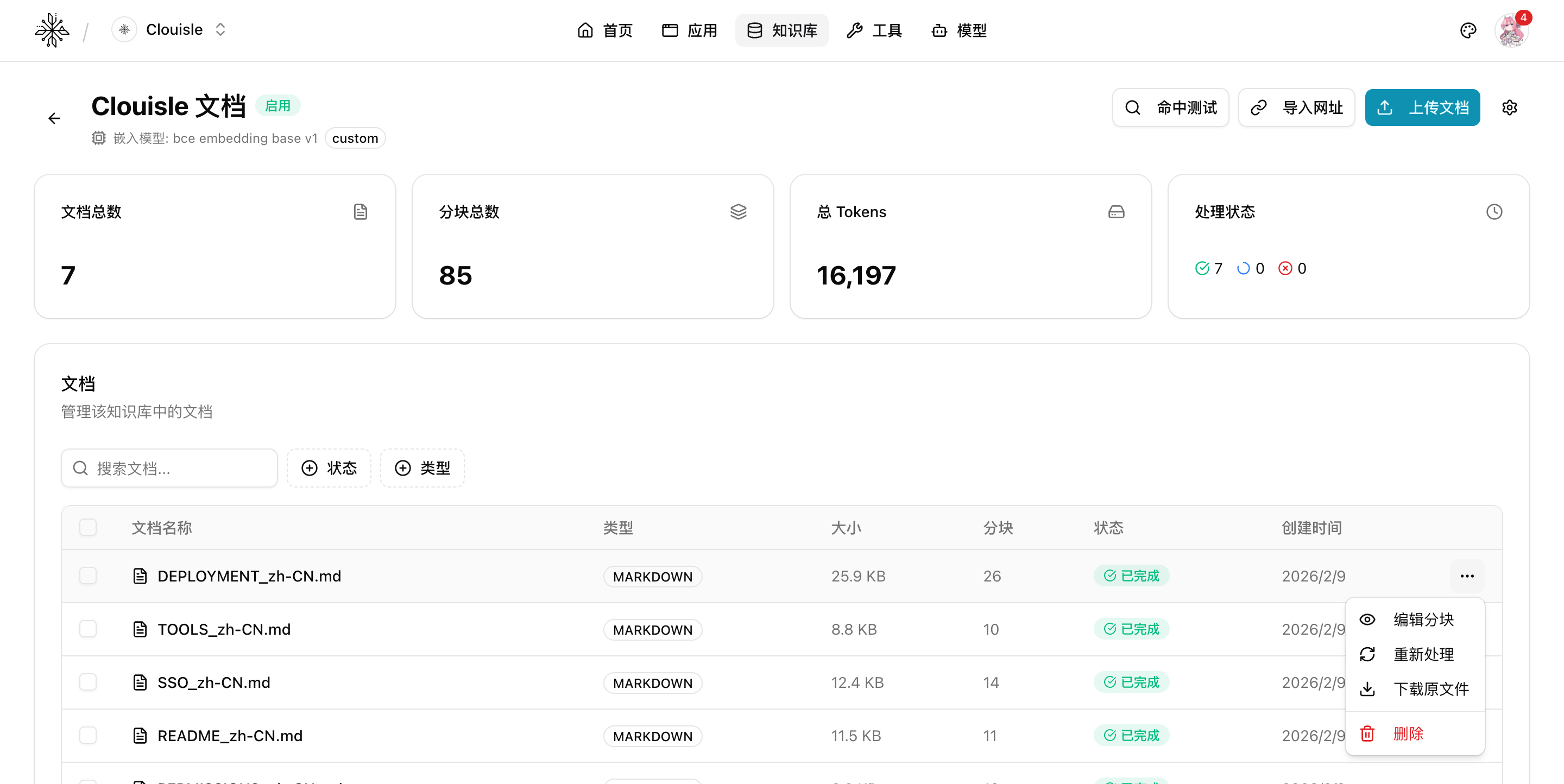
如果这一页里已经能看到文档和分块统计,说明知识库的基础处理链路已经开始生效。
如果需要针对单篇文档继续处理,还可以从文档行的操作菜单里继续:
- 编辑分块
- 重新处理
- 下载原文件
- 删除文档
第 6 步:做检索测试,而不是直接去问 Agent
知识库配置好后,不建议第一时间就拿 Agent 做整体测试。
应先独立验证知识库本身:
- 输入真实问题
- 看是否命中正确文档
- 看返回片段是否真的能支持回答
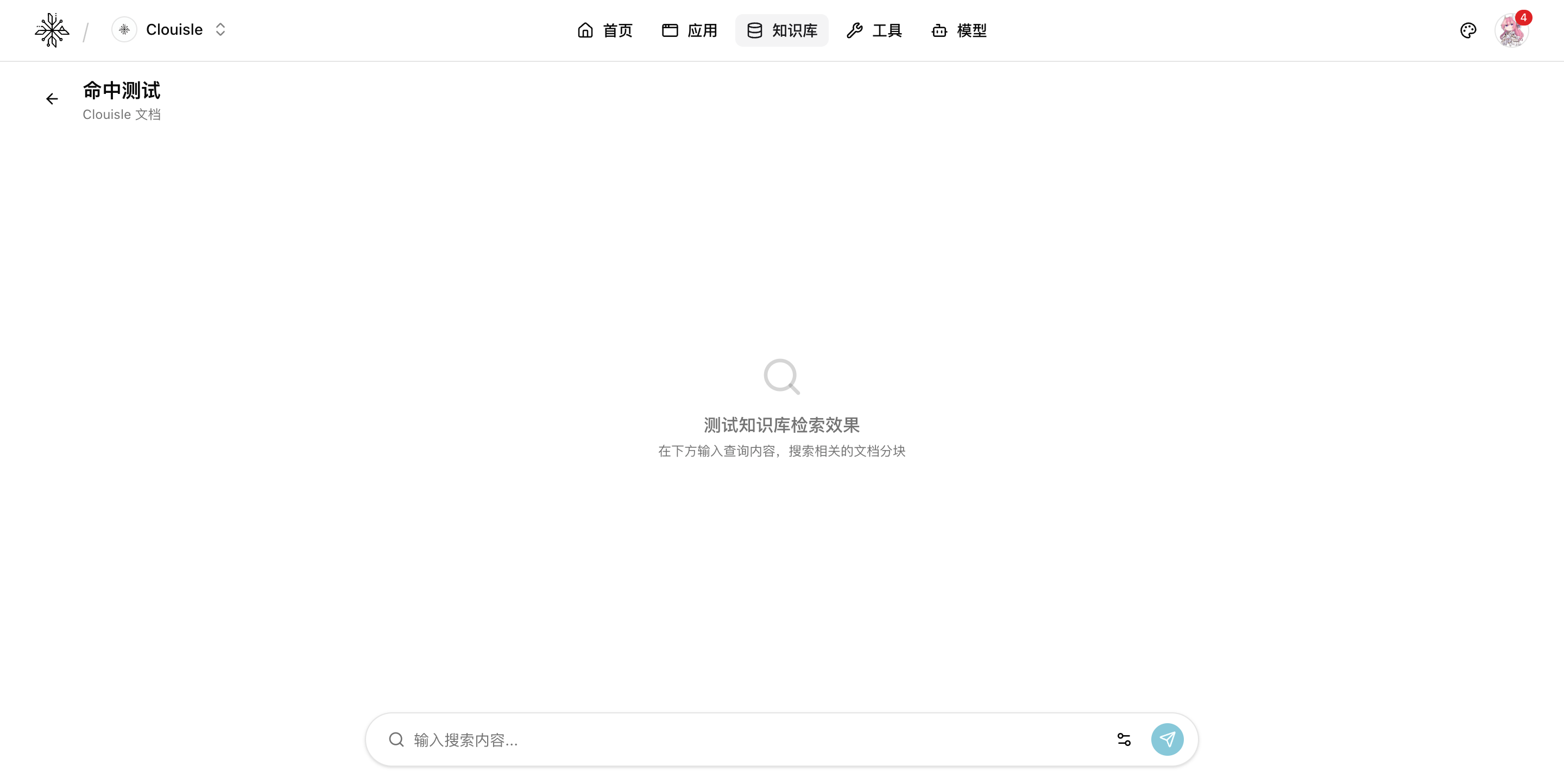
这一步越早做,后面排查 Agent 效果问题越容易。
第 7 步:确认检索稳定后再关联到 Agent 或工作流
只有当检索结果已经比较稳定时,再把知识库接入 Agent 或工作流。
否则后续出现“回答不准”,你会很难判断问题到底出在知识库还是应用配置。
结果验证
一个可用的知识库,至少应满足:
- 在列表页里可以清楚看到它的名称、文档数和分块数
- 进入详情页后能看到文档处理成功
- 用真实问题检索时,能命中正确资料
- 关联到 Agent 后,回答质量有明显提升
常见问题
为什么文档上传成功了,但知识库效果很差
先不要急着换模型,优先检查:
- 文档内容是否过期或重复
- 分块是否过大或过碎
- 检索问题是否写得太像关键词,而不是用户真实问题
为什么知识库详情页有文档数量,但 Agent 还是检索不到
常见原因是:
- 文档还没处理完成
- Agent 没有关联正确的知识库
- 检索阈值或命中数量设置不合适
为什么第一次不建议导入大量资料
因为第一轮最重要的是确认链路可用。
如果一开始就导入大量资料,后续很难判断问题究竟出在文档质量、参数还是检索策略。
注意事项
- 先用少量高质量资料跑通,再逐步扩充
- 知识库应先单独验证,再接入 Agent 或工作流
- 每次大规模调整参数后,都应重新做一轮固定样例测试