模型管理
按接入、配置、测试、投放的顺序把模型沉淀成平台可复用的能力资产。
功能概述
模型管理用于统一接入和维护平台中的各类模型。
只有模型在这里被正确配置、测试并标记能力后,Agent、工作流和知识库才能稳定调用。
适用场景
这一页适合:
- 第一次接入新的模型提供商
- 调整默认模型
- 为不同业务开放不同类型模型
- 排查模型不可用或效果异常
前置条件
开始前建议准备:
- 提供商地址、API Key 和模型标识
- 模型支持的能力说明,例如是否支持视觉、函数调用、流式输出
- 对上下文长度、成本和输出上限的预期
操作步骤
第 1 步:进入模型中心,先看现有模型结构
先进入工作台的 模型 页面,确认当前平台已经接入了哪些模型。
这一步重点看:
- 模型是按什么名称展示的
- 不同提供商是否已有统一命名
- 平台当前主要开放了哪些模型类型
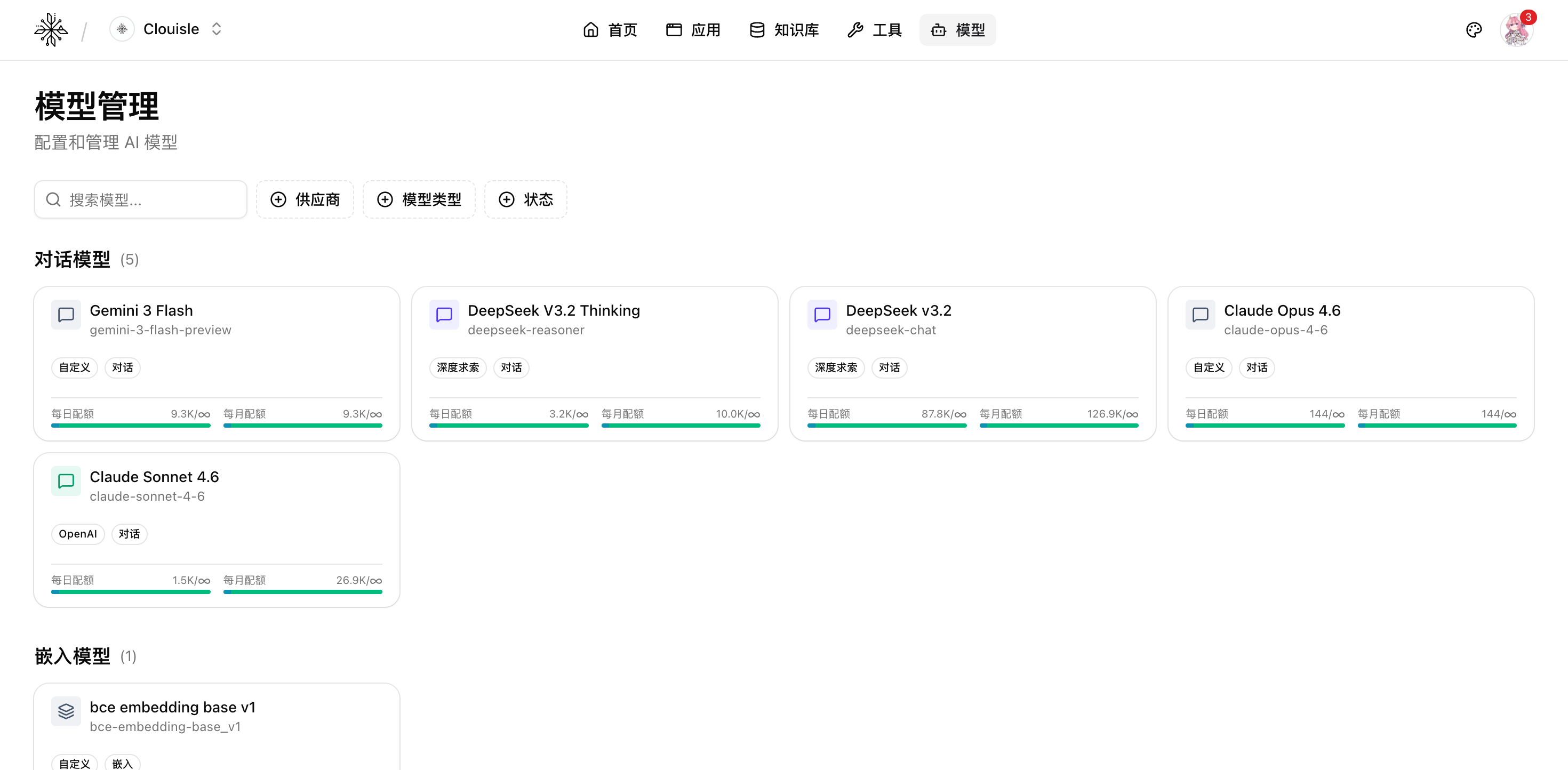
完成这一步后,你应该能判断新模型是新增一类能力,还是补充已有能力档位。
第 2 步:创建模型并填写基础身份信息
新增模型时,先把最基础的身份信息补齐:
- 模型名称
- 提供商
- 模型类型
- 用途说明
名称建议直接体现能力和提供商,例如“OpenAI GPT-4.1”“DeepSeek Chat”“Qwen Embedding”。
不要只写模糊名称,否则后续在 Agent 或工作流里很难分辨。
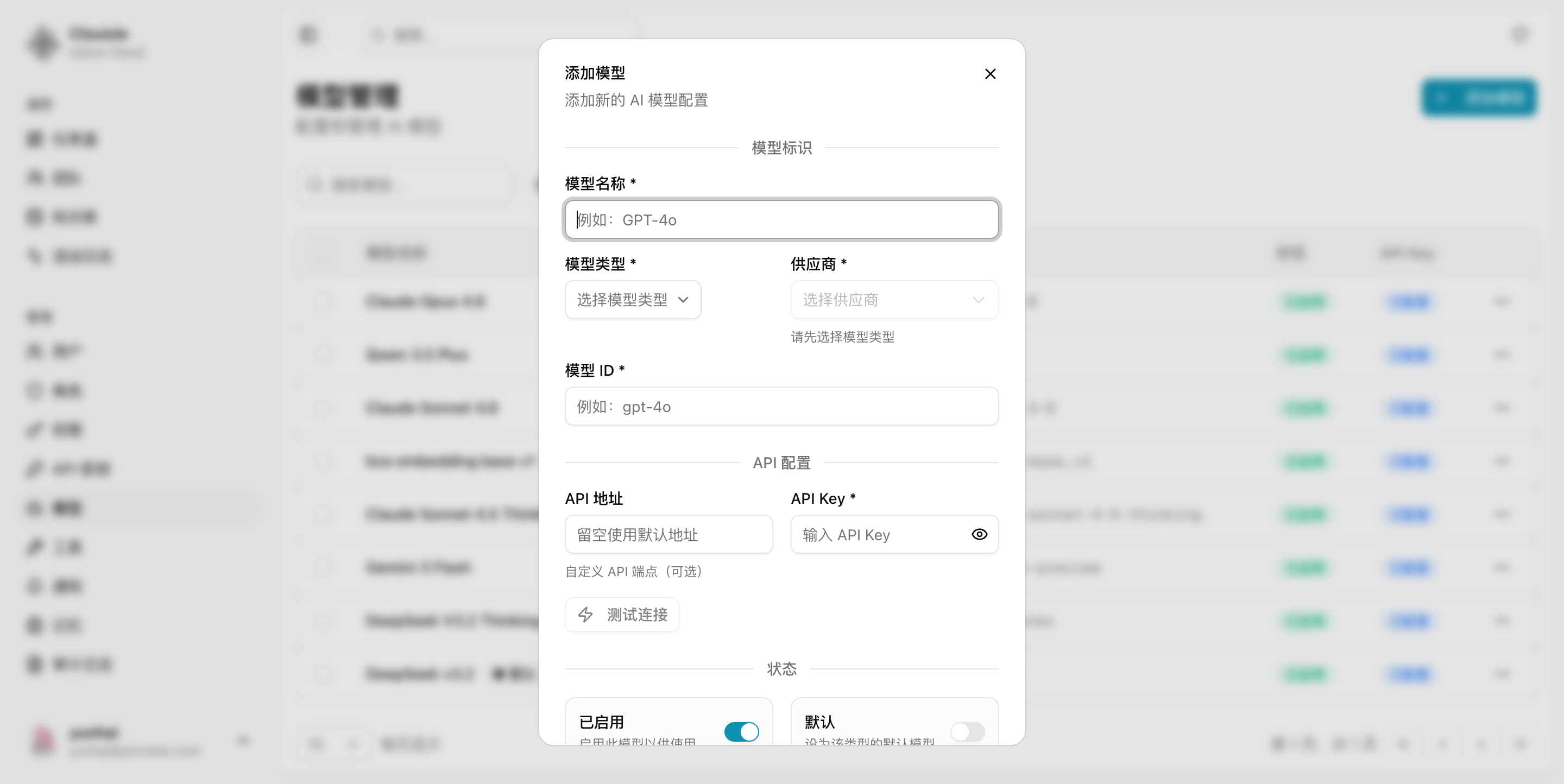
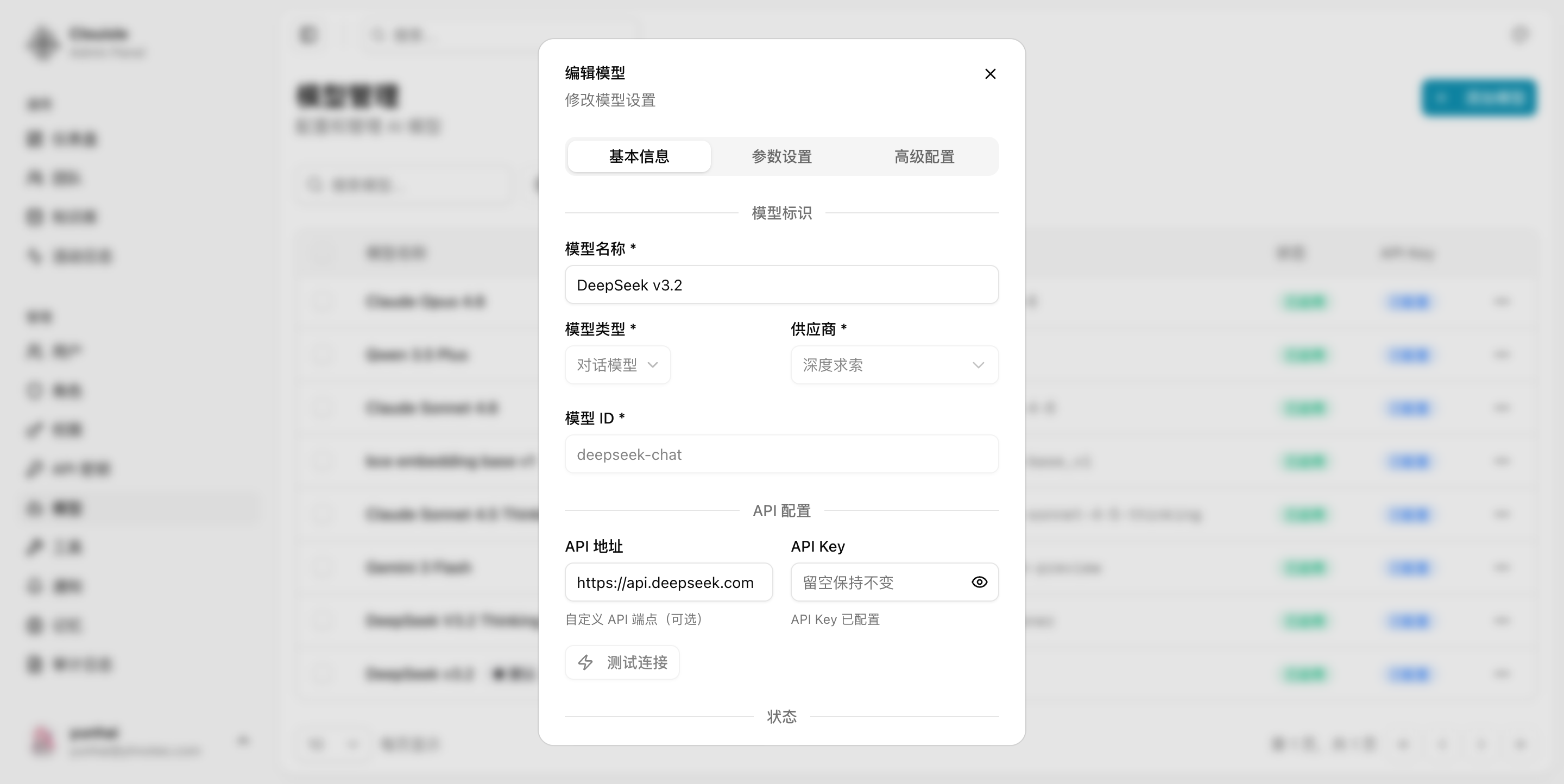
第 3 步:填写 API 接入信息
接下来配置模型真正能调用所需的参数:
- Base URL
- API Key
- 模型标识
这一步的目标不是“先保存再说”,而是确保模型后面能被正常请求。
如果这里配置错误,后面的任何应用层测试都会失败。
如果模型已经创建完成,也可以从模型列表的操作菜单进入编辑弹窗,直接修改基础信息和 API 配置。
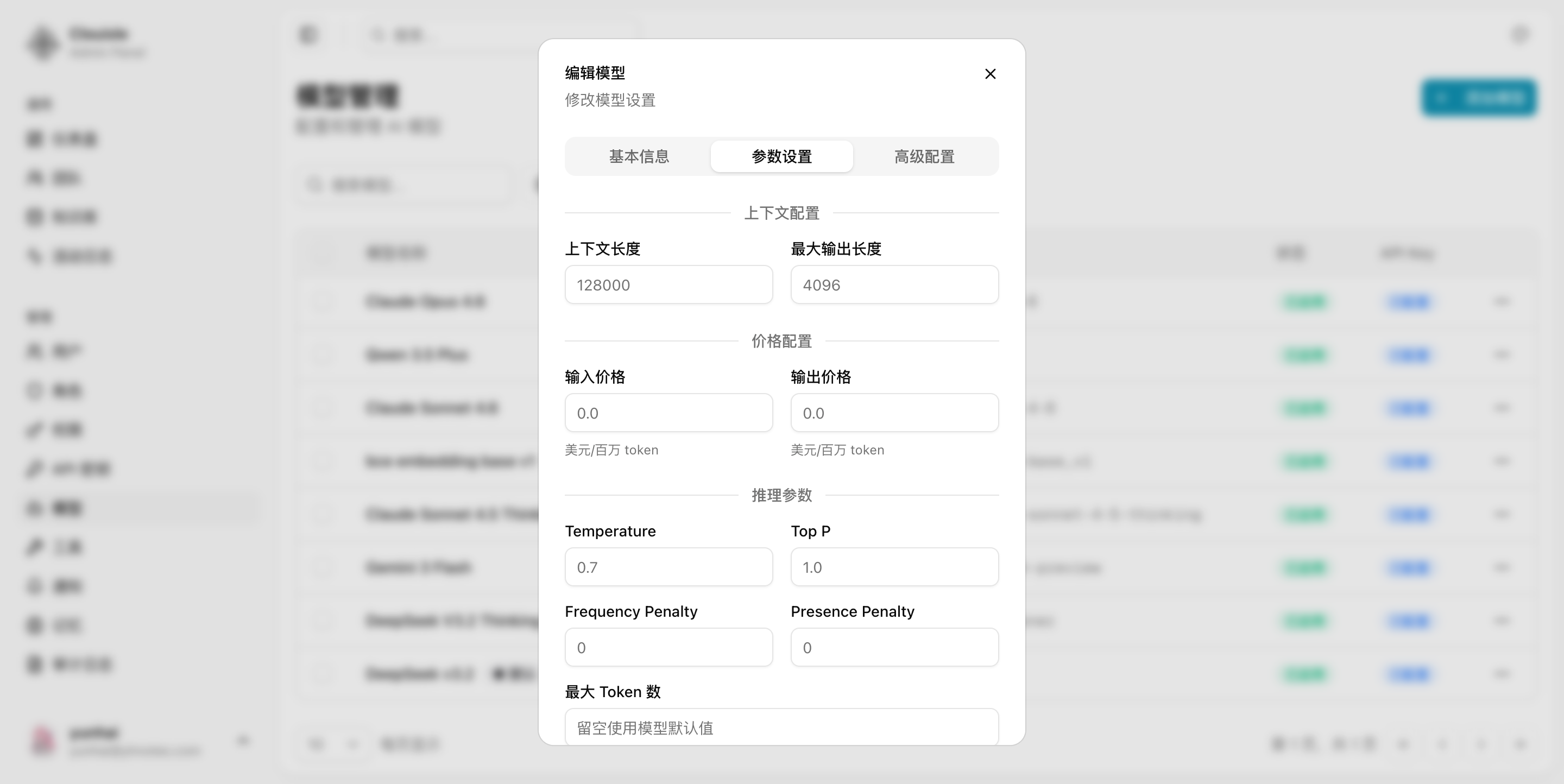
第 4 步:补齐规格、能力标签和默认参数
基础接通后,再补下面这些决定使用体验和治理能力的信息:
- 上下文长度
- 最大输出 Token
- 是否支持视觉、函数调用、流式响应
- 默认推理参数,例如
temperature、top_p - 输入输出价格
这些配置的意义不只是展示,它们会直接影响:
- 应用层的模型选择判断
- 团队授权和成本控制
- 后续故障排查
第 5 步:执行模型测试
接入完成后,必须立即做一次测试,而不是等到 Agent 里再发现问题。
测试时重点确认:
- 能否成功返回结果
- 返回速度是否在可接受范围内
- 关键能力是否真的支持,例如视觉或流式输出
只有这一步通过,模型才适合进入下一步投放。
在模型列表的操作菜单里,通常可以直接找到 测试连接 入口。
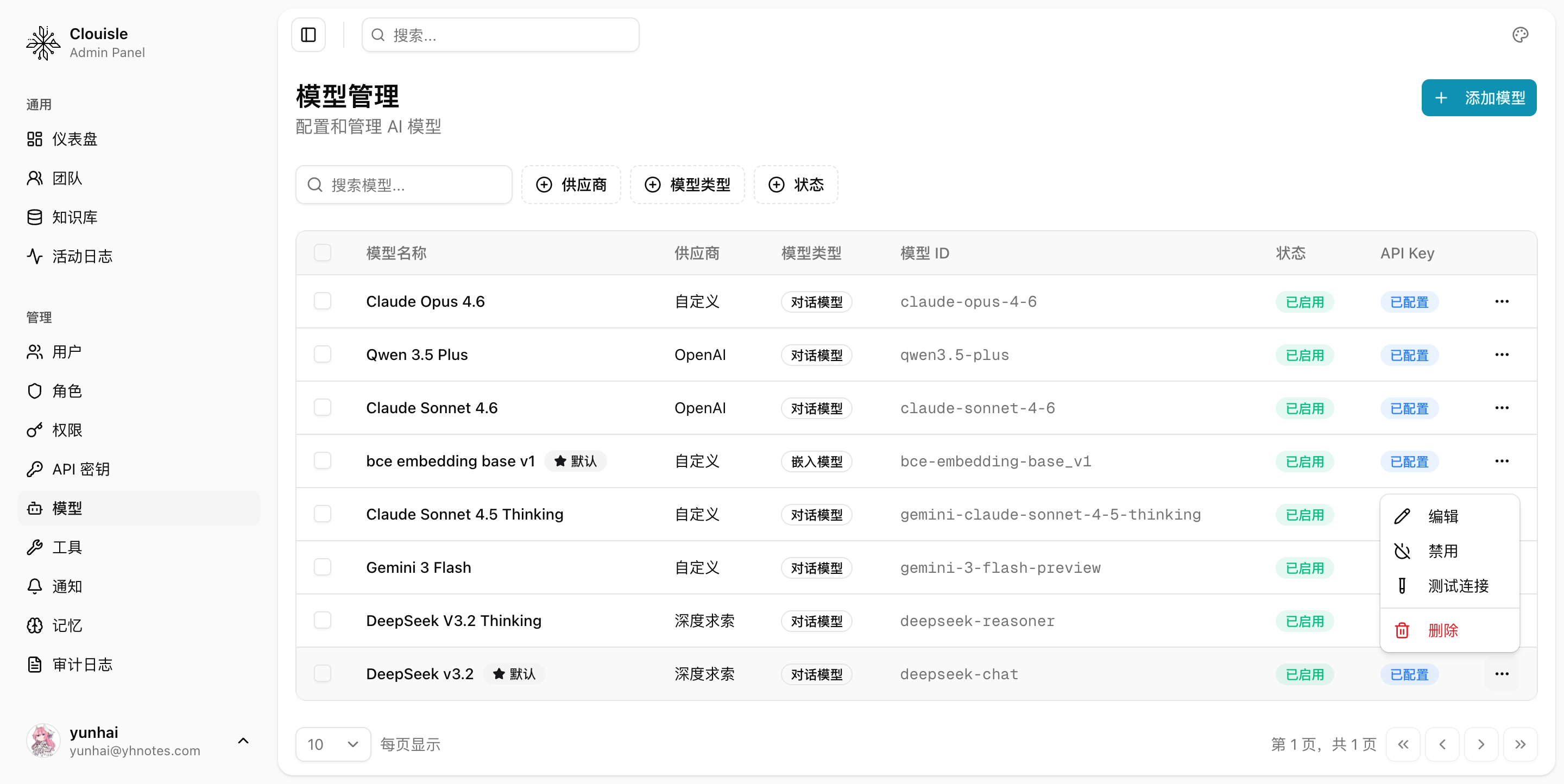
执行后,应至少看到明确的成功或失败反馈,而不是只看保存是否成功。
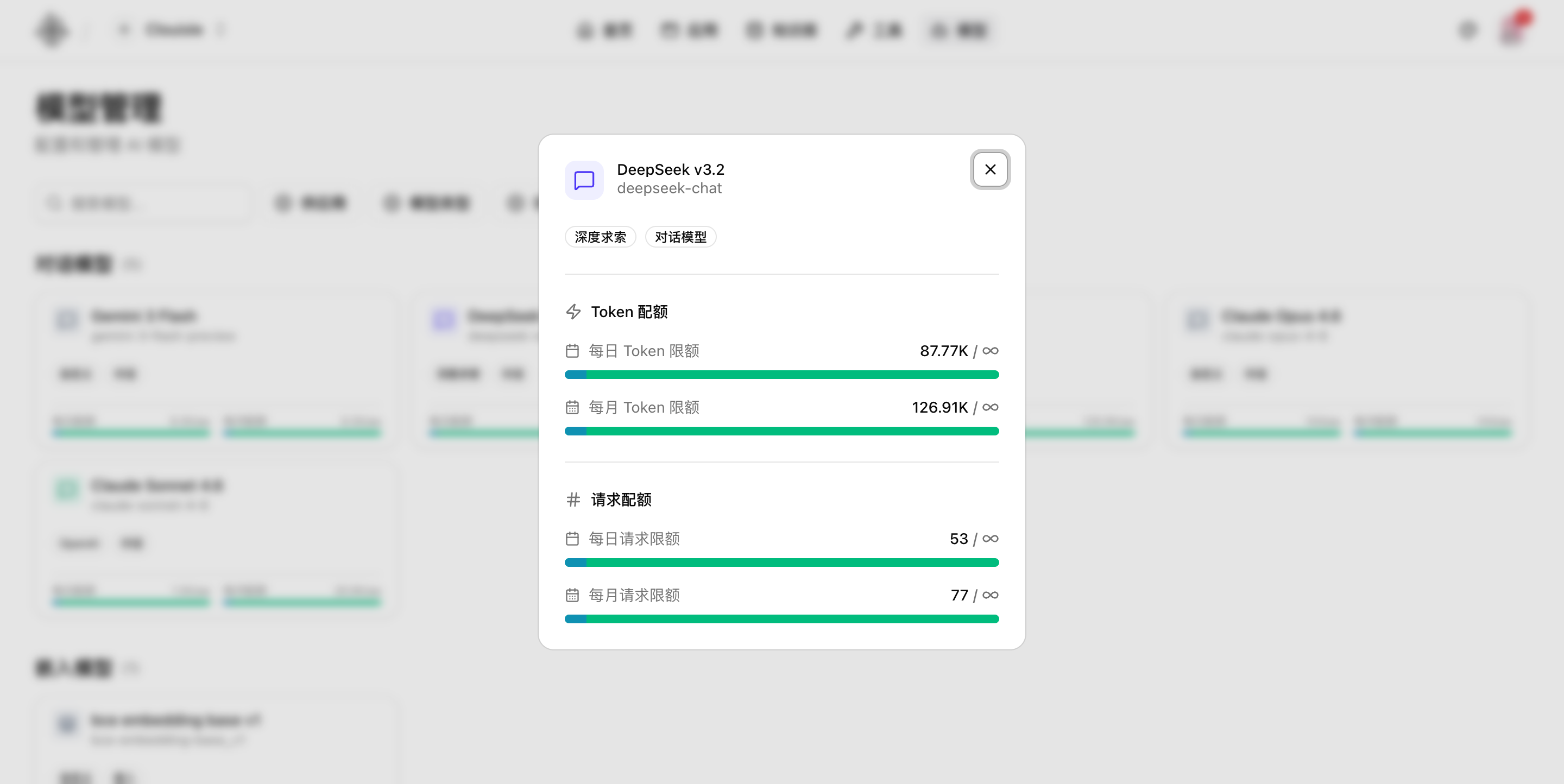
如果当前页面还没有进入完整的测试流,至少也要先打开模型详情,确认它的配额和基础状态可读、可核对。
第 6 步:在 Agent、工作流或知识库里做二次验证
模型中心测试通过后,再到真实使用场景里选中该模型,确认:
- Agent 中能正常回答
- 工作流节点能正常运行
- 如果是 Embedding 模型,知识库处理链路可以跑通
结果验证
一个可投入使用的模型,至少应满足:
- 在模型中心中可清楚识别其名称和用途
- 测试功能可以成功返回结果
- 在实际模块中可以被正常选择和调用
- 能力标签和价格信息基本完整
常见问题
为什么模型中心里保存成功了,但 Agent 里还是报错
优先检查:
- Base URL 和模型标识是否正确
- API Key 是否有效
- Agent 所在模块是否真的支持该模型类型
为什么不建议接入后直接给所有人用
因为模型接通不代表效果稳定。
正确做法是先做模型中心测试,再在少量 Agent 或工作流里验证,最后再扩大开放范围。
为什么价格和能力标签也要填
这两项会直接影响团队授权、默认模型选择和成本判断。
如果留空,平台后续治理会变得非常被动。
注意事项
- 新模型先测试、再小范围投放、最后再全量开放
- 名称、能力标签和价格信息要从一开始就保持规范
- 默认模型调整前,要评估对现有应用的连带影响