文档管理与检索测试
按导入样本、检查处理结果、查看分块和做真实问题检索的顺序验证知识库效果。
功能概述
知识库是否真正可用,关键取决于两件事:
- 文档有没有被正确处理
- 检索能不能把正确内容找出来
这一页聚焦的就是这两条最核心的落地链路。
适用场景
适合:
- 第一次导入文档
- 调整分块策略后复测效果
- Agent 明明接了知识库却回答不准
前置条件
开始前建议准备:
- 一组真实业务问题
- 这些问题对应的标准资料来源
- 至少一个已经创建好的知识库
操作步骤
第 1 步:先导入少量高质量样本,不要全量上来就灌
第一次导入资料时,建议只选少量高质量文档作为样本。
优先选择:
- 结构清晰
- 主题集中
- 版本较新
- 文本可解析
的资料。
这样后面即使出现问题,也更容易判断是资料质量还是参数问题。
第 2 步:先确认文档处理状态,而不是只看上传成功
上传后,重点检查:
- 是否处理成功
- 是否有失败或卡住的文档
- 文档数量和分块数量是否大致合理
很多问题不是出在检索,而是文档根本没处理完成。
第 3 步:再查看分块结果是否符合预期
如果页面支持分块预览,建议重点看:
- 一段内容是否被切得过碎
- 标题和正文是否被拆散
- 表格、列表或代码块是否被破坏
分块不合理时,后面的检索再怎么调也很难稳定。
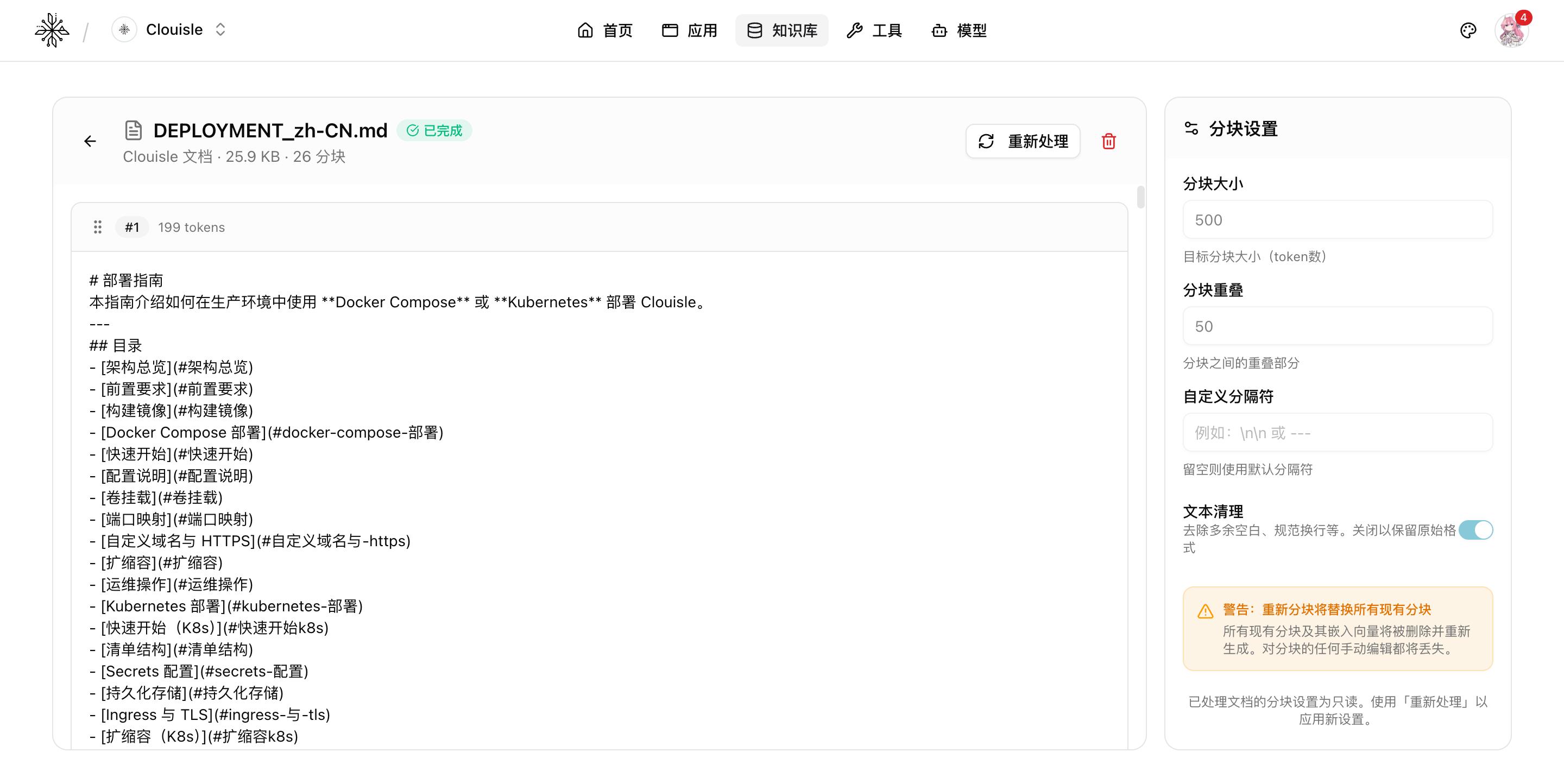
在分块详情里,建议重点核对:
- 每个分块的 token 数是否大致均衡
- 文本切分位置是否自然
- 当前分块设置是否还能继续复用
第 4 步:用真实问题做检索测试,而不是只搜关键词
测试时应直接输入用户未来真正会问的问题,而不是只搜文档标题。
重点观察:
- 是否命中正确文档
- 返回数量是否合适
- 是否有太多噪声内容混进来
第 5 步:把检索结果和最终回答分开判断
如果 Agent 回答不准,不要立刻把问题归咎于模型。
先判断:
- 检索本身有没有命中正确文档
- 返回片段是否足够支持回答
先把知识库链路看清楚,再回到 Agent 层继续排查。
结果验证
一轮合格的文档与检索测试,至少应满足:
- 文档处理状态正常
- 分块结构基本合理
- 真实问题能命中正确资料
- 返回片段足够支持后续回答
常见问题
为什么上传成功了,但知识库还是像没资料一样
通常是因为文档还没有真正处理完成,或者分块结果已经失真。
为什么测试不能只搜关键词
因为真实用户提问通常不是关键词搜索。
如果只用关键词测,你很难提前发现实际问答中的命中问题。
为什么 Agent 回答不准时要先查检索
因为只要知识没有命中正确内容,后面的模型再强也很难生成正确答案。
注意事项
- 先做小样本验证,再扩大导入规模
- 文档测试和 Agent 测试应分层进行
- 每次大规模导入或参数调整后,都要重新做样例回归