工作流监控
按看趋势、找失败样本、回放执行日志和反馈优化的顺序持续监控工作流。
功能概述
工作流监控用于回答两个关键问题:
- 这条流程是不是在稳定运行
- 出问题时应该先从哪里开始查
它不只是看“跑了多少次”,更重要的是帮你找到失败分布、耗时异常和节点级问题。
适用场景
适合:
- 工作流已经开始对外提供服务
- 需要持续观察成功率和耗时
- 需要排查 Webhook、定时任务或外部系统接入问题
前置条件
开始前建议具备:
- 已发布的工作流
- 一定量真实执行记录
- 一组关键业务成功标准
操作步骤
第 1 步:先看整体趋势,不要直接钻进单条日志
查看工作流监控时,第一眼先看总体数据:
- 总运行次数
- 成功率
- 平均耗时
- 失败次数
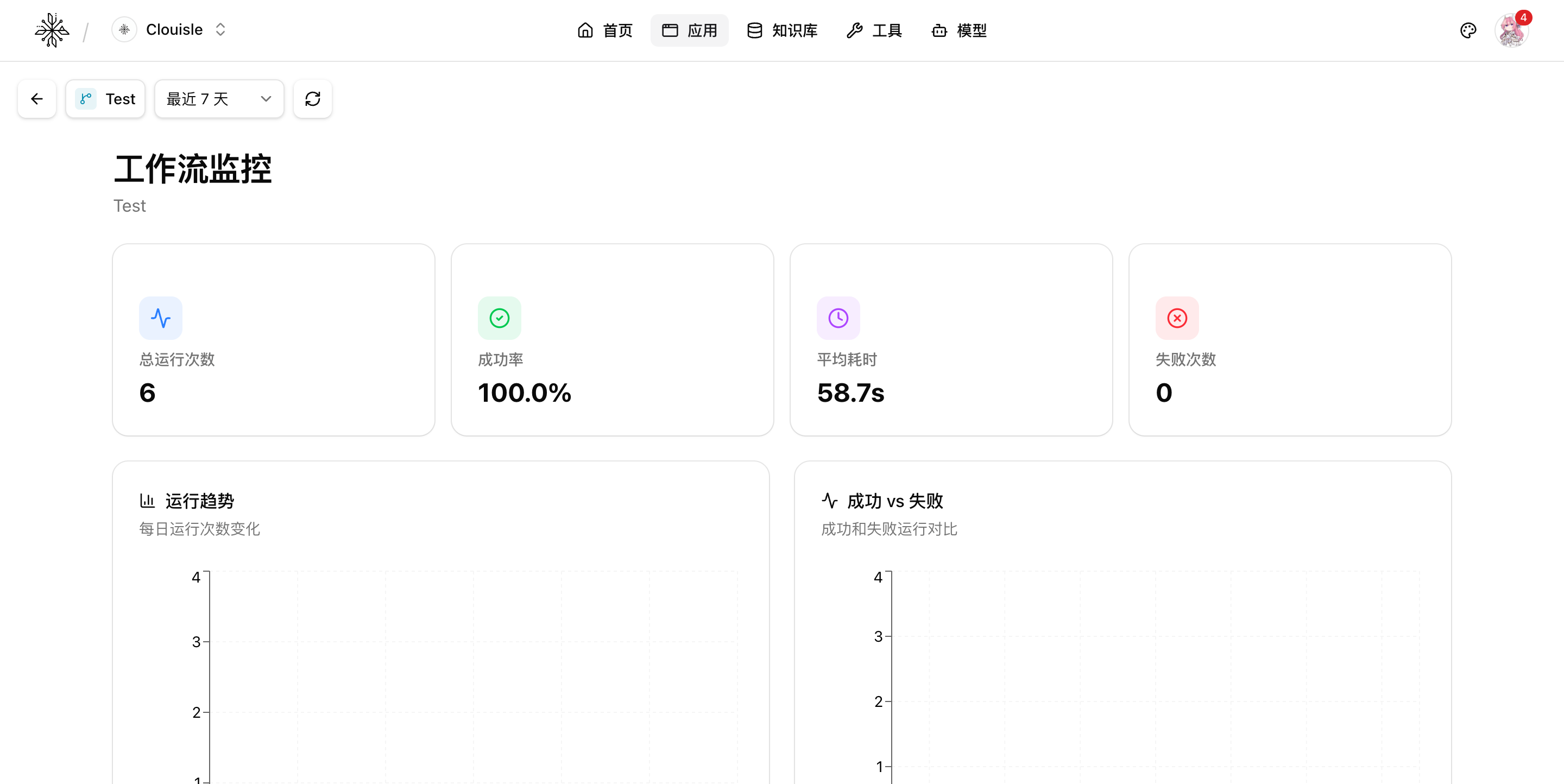
这一步的目的,是先判断问题是偶发、局部还是系统性。
如果你一开始就只盯单条失败日志,很容易误判整体状态。
第 2 步:再筛失败样本,看异常是否集中
当你发现成功率下降或失败增加后,再去看失败记录。
重点判断:
- 是否集中在某个节点
- 是否集中在某类输入
- 是否与某个外部系统、模型或工具有关
如果失败样本高度集中,通常说明问题不是随机波动,而是某个固定环节出了问题。
第 3 步:回放执行日志,还原真实执行链路
进入具体执行记录后,重点还原下面几个问题:
- 输入是什么
- 流程是按什么路径执行的
- 哪一步开始偏离预期
- 失败后影响了哪些下游步骤
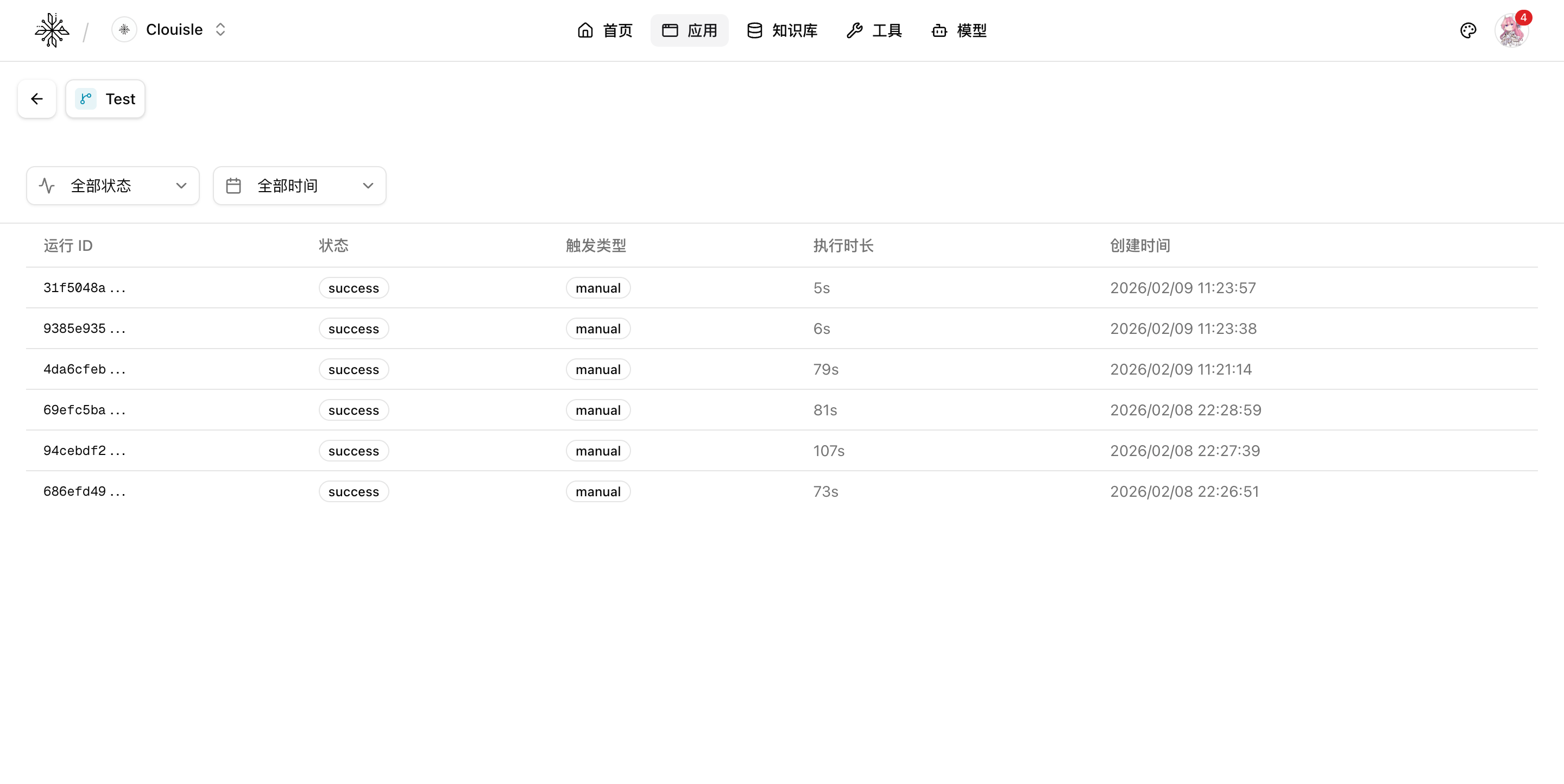
这一阶段不要急着改流程,先把“问题发生在哪里”看清楚。
第 4 步:区分是流程设计问题,还是外部依赖问题
日志看清后,建议再做一次分类判断:
- 如果问题稳定出现在某个节点,优先回流程设计
- 如果问题只在特定时间或外部调用时出现,优先查依赖系统
- 如果问题主要体现在高耗时而非失败,优先查模型、工具和网络链路
第 5 步:把监控结果反向用于优化和发布
监控的终点不是“看过了”,而是推动改进。
建议把结论带回:
- 节点设计
- 超时和重试策略
- 工具调用方式
- Webhook 或定时任务配置
结果验证
一个有效的工作流监控体系,至少应满足:
- 团队能快速判断流程整体是否稳定
- 出现异常时能快速定位到失败环节
- 日志足以支持复盘和优化决策
常见问题
为什么只看总运行次数没有意义
因为运行次数只代表流量,不代表质量。
如果不结合成功率、耗时和失败分布,很难判断工作流是否真的健康。
为什么同一类失败总在重复出现
通常说明问题来自固定节点或固定依赖,而不是偶发波动。
这时应优先修流程或依赖,而不是靠人工重试掩盖问题。
为什么监控看起来没问题,但用户还是说慢
这往往意味着平均耗时掩盖了长尾问题。
应进一步筛高耗时样本,而不是只看平均值。
注意事项
- 先看趋势,再看个例,排查顺序不要反过来
- 高频失败应优先修根因,不要长期依赖人工补救
- 外部系统联动越多,越要保留完整执行记录