Document Management and Retrieval Testing
Validate knowledge base results in the order of importing samples, checking processing results, viewing chunks, and running real-question retrieval.
Feature Overview
Whether a knowledge base is truly usable depends mainly on two things:
- Whether documents are processed correctly
- Whether retrieval can find the correct content
This page focuses on these two most essential implementation paths.
Use Cases
Suitable for:
- Importing documents for the first time
- Retesting results after adjusting chunking strategy
- Cases where an Agent has clearly connected to a knowledge base but answers inaccurately
Prerequisites
Before you start, we recommend preparing:
- A set of real business questions
- The standard material sources corresponding to these questions
- At least one knowledge base that has already been created
Steps
Step 1: Import a small number of high-quality samples first instead of uploading everything at once
When importing materials for the first time, we recommend selecting only a small number of high-quality documents as samples. Prioritize materials that are:
- Clearly structured
- Focused in topic
- Relatively recent in version
- Text-parseable
This makes it easier to determine whether issues come from material quality or parameters if problems appear later.
Step 2: Confirm document processing status first instead of only checking upload success
After uploading, focus on checking:
- Whether processing succeeded
- Whether any documents failed or are stuck
- Whether the document count and chunk count are roughly reasonable
Many issues do not come from retrieval. They happen because the documents were never fully processed.
Step 3: Then check whether chunking results meet expectations
If the page supports chunk preview, we recommend focusing on:
- Whether a section of content is cut too finely
- Whether headings and body text are split apart
- Whether tables, lists, or code blocks are damaged
When chunking is unreasonable, retrieval will be hard to stabilize no matter how parameters are tuned later.
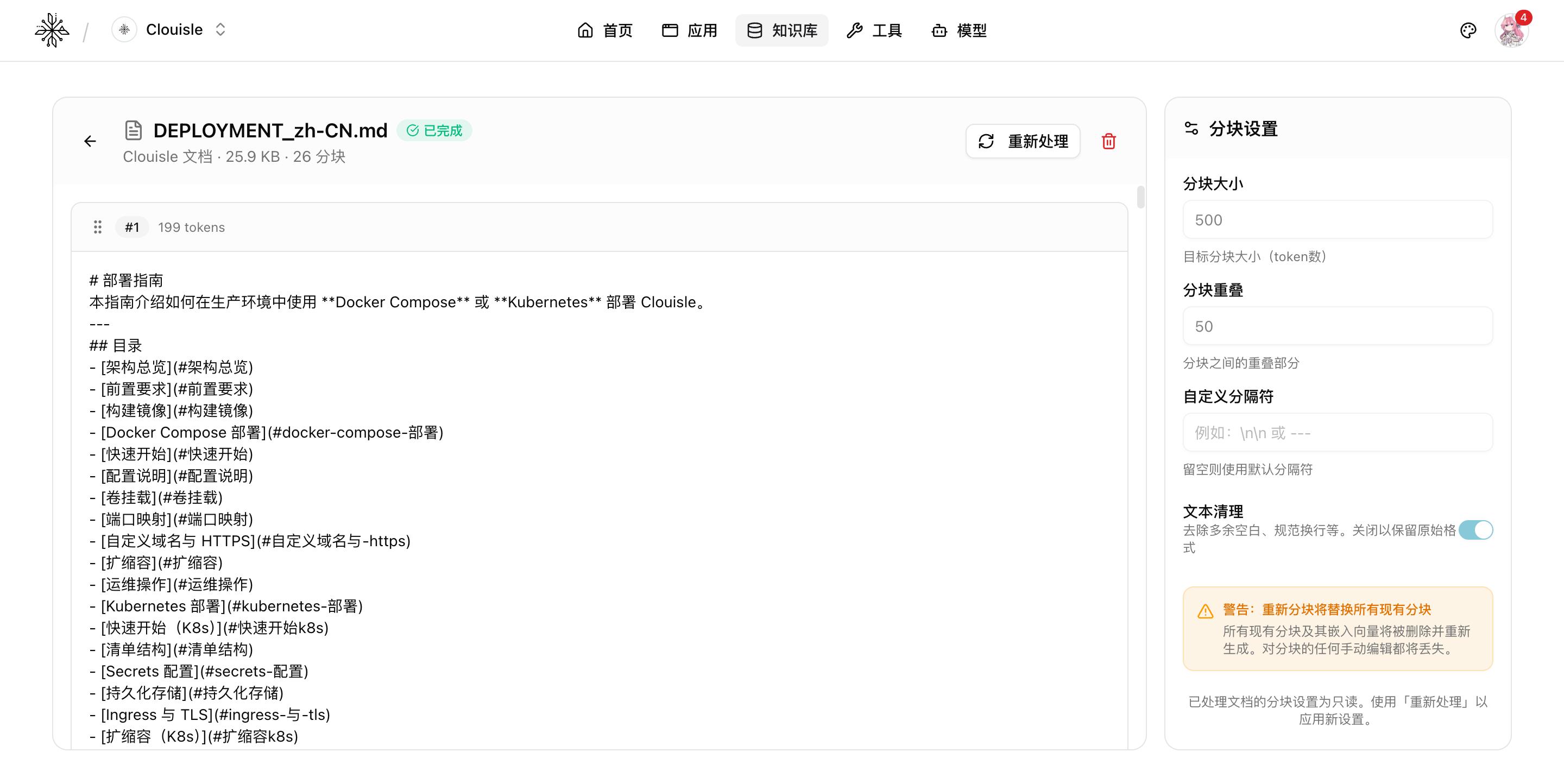
In chunk details, we recommend focusing on:
- Whether each chunk's token count is roughly balanced
- Whether text split positions are natural
- Whether the current chunking settings can continue to be reused
Step 4: Use real questions for retrieval testing instead of only searching keywords
During testing, directly enter questions users will actually ask in the future, instead of only searching document titles. Focus on observing:
- Whether the correct document is hit
- Whether the returned count is appropriate
- Whether too much noisy content is mixed in
Step 5: Judge retrieval results and final answers separately
If the Agent answers inaccurately, do not immediately blame the model. First judge:
- Whether retrieval itself hit the correct document
- Whether the returned snippets are sufficient to support the answer
Clarify the knowledge base chain first, then return to the Agent layer for further troubleshooting.
Result Validation
A qualified round of document and retrieval testing should meet at least these criteria:
- Document processing status is normal
- Chunk structure is basically reasonable
- Real questions can hit the correct materials
- Returned snippets are sufficient to support later answers
FAQ
Why did the upload succeed, but the knowledge base still seems to have no materials?
Usually because the documents have not actually finished processing, or the chunking results are already distorted.
Why should testing not only search keywords?
Because real user questions are usually not keyword searches. If you only test with keywords, it is hard to discover hit issues in real Q&A ahead of time.
Why check retrieval first when Agent answers are inaccurate?
Because as long as knowledge does not hit the correct content, even a stronger model will struggle to generate the correct answer.
Notes
- Validate with small samples first, then expand the import scale
- Document testing and Agent testing should be performed in separate layers
- After every large-scale import or parameter adjustment, rerun sample regression tests
Knowledge Base
Build a knowledge base that can truly be used for RAG in the order of creation, import, processing, and retrieval validation.
Knowledge Base Optimization
Continuously optimize knowledge base results in the order of material quality, chunking strategy, retrieval parameters, and fixed-sample regression.